PHP 正则表达式匹配不包含一个词的一行
我知道有可能匹配一个单词,然后使用其他工具进行反向匹配(例如grep -v)。然而,是否有可能使用正则表达式来匹配不包含特定单词的行,例如hede?
Input:
hoho
hihi
haha
hede
Code:
grep "<Regex for 'doesn't contain hede'>" input
Desired output:
hoho
hihi
haha
([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$)))*?这个想法很简单。一直匹配到你看到不需要的字符串的开头,然后只在字符串未完成的N-1种情况下进行匹配(其中N是字符串的长度)。这N-1种情况是"h后面是non-e","he后面是non-d",以及"hed后面是non-e"。如果你成功地通过了这N-1种情况,你就成功地没有匹配了不需要的字符串,所以你可以再次开始寻找[^h]*。
- stevendesu 2011-09-29
^([^h]*(h([^e]|$)|he([^d]|$)|hed([^e]|$))?)*$ 当"hede"的实例前面有"hede"的部分实例时,这就失败了,例如在"hhede"中。
- jaytea 2012-09-10
regex不支持反向匹配的说法并不完全正确。你可以通过使用负向查找法来模仿这种行为。
^((?!hede).)*$
非俘获性变体。
^(?:(?!:hede).)*$
上面的正则表达式将匹配任何字符串,或没有换行符的行,不包含(子)字符串'hede'。如前所述,这不是正则表达式“擅长”(或应该做)的事情,但它仍然是可能的。
如果你也需要匹配断行符,请使用DOT-ALL修饰符(以下模式中的尾部s):
/^((?!hede).)*$/s
或在内联中使用它。
/(?s)^((?!hede).)*$/
(其中/.../是重合字符定界符,即不属于模式的一部分)
如果 DOT-ALL 修饰符不可用,您可以使用字符类 [\s\S] 模拟相同的行为:
/^((?!hede)[\s\S])*$/
Explanation
一个字符串只是一个n字符的列表。在每个字符之前和之后,都有一个空字符串。所以一个n字符的列表会有n+1个空字符串。考虑一下字符串 "ABhedeCD":
┌──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┬───┬──┐
S = │e1│ A │e2│ B │e3│ h │e4│ e │e5│ d │e6│ e │e7│ C │e8│ D │e9│
└──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┴───┴──┘
index 0 1 2 3 4 5 6 7
,其中的e是空字符串。重组词(?!hede).向前看,看是否没有子串"hede"被看到,如果是这样(所以看到了别的东西),那么.(点)将匹配任何字符,除了换行。Look-arounds也被称为零宽度断言,因为它们不消耗任何字符。它们只断言/验证一些东西。
因此,在我的例子中,每一个空字符串首先被验证,看前面是否没有"hede",然后再由.(点)消耗一个字符。重组词(?!hede).只会做一次,所以它被包裹在一个组中,并重复零次或多次。((?!hede).)*.最后,输入的开始和结束被固定下来,以确保整个输入被消耗。^((?!hede).)*$
正如你所看到的,输入"ABhedeCD"将失败,因为在e3上,重码(?!hede)失败了(前面有is "hede"!)。
grep)都有支持 regex 的功能,从理论上讲,它们都是非规则的。
- Bart Kiers 2016-11-18
^\(\(hede\)\@!.\)*$
- baldrs 2016-11-24
请注意,的解决方案并非以“hede”开头:
^(?!hede).*$
通常比解决不包含“hede”的解决方案更有效:
^((?!hede).)*$
前者只在输入字符串的第一个位置检查 "hede",而不是在每一个位置都检查。
(.*)(?<!hede)$.@Nyerguds'的版本也可以做到,但完全忽略了答案中提到的性能问题。
- thisismydesign 2017-09-14
^((?!hede).)*$?使用^(?!.*hede).*$不是更有效吗?它做同样的事情,但步骤更少
- JackPRead 2019-01-15
如果你只是用它来做grep,你可以用grep -v hede来获得所有不含hede的行。
ETA 哦,重新阅读问题,grep -v 可能就是您所说的“工具选项”。
grep -v -e hede -e hihi -e ...
- Olaf Dietsche 2015-04-26
grep -v "hede\|hihi" :)
- Putnik 2016-12-09
grep -vf pattern_file file来处理。
- codeforester 2018-03-11
egrep或grep -Ev "hede|hihi|etc",以避免尴尬的转义。
- Amit Naidu 2018-06-03
答案是:
^((?!hede).)*$
解释:
^字符串的开头,(分组并捕获到/1(0或更多的次数(尽可能多的匹配)),
(?!向前看,看看有没有,
hede你的字符串,
) 预读结束,
. 任何字符,除了 \n,
)* end of \1 (注意:因为您在此捕获中使用了量词,所以只有捕获模式的 LAST 重复将存储在 \1 中)
$ 在可选的 \n 之前,以及字符串的结尾
^((?!DSAU_PW8882WEB2|DSAU_PW8884WEB2|DSAU_PW8884WEB).)*$',对我来说是有效的。
- Damodar Bashyal 2015-08-11
给定的答案完全没有问题,只是一个学术性的问题。
理论计算机科学意义上的常规表达式不能够这样做。对他们来说,它必须看起来像这样。
^([^h].*$)|(h([^e].*$|$))|(he([^h].*$|$))|(heh([^e].*$|$))|(hehe.+$)
这只是做一个完整的匹配。为子匹配做这件事甚至会更尴尬。
(hede|Hihi)'这样的表达式的'或',是否在任何可能的正则语言的范围内?(这也许是CS的一个问题。)
- James Haigh 2014-06-13
如果您希望正则表达式测试仅在整个字符串匹配时失败,则以下方法将起作用:
^(?!hede$).*
例如 -- 如果你想允许除 "foo "以外的所有值(即 "foofoo"、"barfoo "和 "foobar "将通过,但 "foo "将失败),使用。^(?!foo$).*
当然,如果你要检查精确的平等,在这种情况下,一个更好的通用解决方案是检查字符串的平等,即
myStr !== 'foo'
如果你需要任何regex特性(这里是指大小写不敏感和范围匹配),你甚至可以把否定词放在测试之外。
!/^[a-f]oo$/i.test(myStr)
本答案顶部的重词解决方案可能是有帮助的,但是,在需要进行正面重词测试的情况下(也许是由API要求的)。
" hede "时失败?
- eagor 2017-05-12
\s指令匹配单一的空白字符
- Roy Tinker 2017-05-12
^(?!\s*hede\s*$).*
- Roy Tinker 2017-05-15
由于正则语言(又称有理语言)在互补下是封闭的,所以总是有可能找到一个正则表达式(又称有理表达式)来否定另一个表达式。但是没有多少工具能实现这一点。
Vcsn支持这个运算符(它表示{c},后缀)。
你首先定义你的表达式的类型:标签是字母(lal_char),例如从a到z中挑选(当然,在使用补充法时,定义字母表是非常重要的),而为每个词计算的 "值 "只是一个布尔值。true,该词被接受,false,被拒绝。
在Python中。
In [5]: import vcsn
c = vcsn.context('lal_char(a-z), b')
c
Out[5]: {a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z} → 𝔹
然后你输入你的表达方式。
In [6]: e = c.expression('(hede){c}'); e
Out[6]: (hede)^c
将这个表达式转换为自动机。
In [7]: a = e.automaton(); a
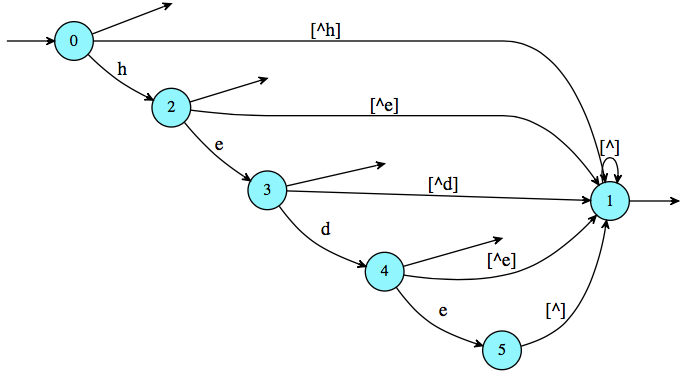{kind=link}
最后,将这个自动机转换回一个简单的表达式。
In [8]: print(a.expression())
\e+h(\e+e(\e+d))+([^h]+h([^e]+e([^d]+d([^e]+e[^]))))[^]*
其中+ 通常表示|,\e 表示空字,[^] 通常写作.(任何字符)。所以,稍微重写一下()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*。
egrep的情况下,重新定义式()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*没有发挥作用。它与hede相匹配。我还试着把它锚定在开头和结尾,但还是不成功。
- Pedro Gimeno 2016-12-06
|之间的优先级不会很好地发挥。'^(()|h(ed?)?|([^h]|h([^e]|e([^d]|d([^e]|e.)))).*)$'.
- akim 2016-12-08
这里有一个很好的解释,说明为什么不容易否定一个任意的regex。不过,我不得不同意其他的答案:如果这不是一个假设性的问题,那么重码就不是这里的正确选择。
在负数前瞻的情况下,正则表达式可以匹配不包含特定模式的东西。这是Bart Kiers的回答和解释。很好的解释!
然而,在Bart Kiers的回答中,lookahead部分会在匹配任何单个字符时提前测试1到4个字符。我们可以避免这种情况,让lookahead部分检查整个文本,确保没有'hede',然后普通部分(.*)可以一次性吃掉整个文本。
这里是改进后的重码。
/^(?!.*?hede).*$/
注意负数前瞻部分的(*?)懒惰量词是可选的,你可以使用(*)贪婪量词来代替,这取决于你的数据:如果'hede'确实存在并且在文本的开头一半,懒惰量词可以更快;否则,贪婪量词会更快。然而,如果'hede'不存在,两者的速度就会相等。
这里是样板代码。
有关前瞻的更多信息,请查看精彩文章:掌握前瞻和后瞻。
此外,请查看RegexGen.js,这是一个JavaScript正则表达式生成器,有助于构建复杂的正则表达式。使用RegexGen.js,您可以以更可读的方式构建正则表达式。
var _ = regexGen;
var regex = _(
_.startOfLine(),
_.anything().notContains( // match anything that not contains:
_.anything().lazy(), 'hede' // zero or more chars that followed by 'hede',
// i.e., anything contains 'hede'
),
_.endOfLine()
);
^(?!.*(str1|str2)).*$
- S.Serpooshan 2017-03-01
^(?!.*?(?:str1|str2)).*$,这取决于你的数据。添加了?:,因为我们不需要捕捉它。
- amobiz 2017-03-02
Benchmarks
我决定评估一些提供的选项并比较它们的性能,并使用一些新功能。 .NET 正则表达式引擎的基准测试:http://regexhero.net/tester/
Benchmark Text:
前7行不应该匹配,因为它们包含搜索到的表达式,而后7行应该匹配!
在这一过程中,我们可以看到,有很多人都不知道该怎么做。
Regex Hero is a real-time online Silverlight Regular Expression Tester.
XRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex HeroRegex HeroRegex HeroRegex HeroRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her Regex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.Regex Hero
egex Hero egex Hero egex Hero egex Hero egex Hero egex Hero Regex Hero is a real-time online Silverlight Regular Expression Tester.
RRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRegex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her
egex Hero
egex Hero is a real-time online Silverlight Regular Expression Tester.
Regex Her is a real-time online Silverlight Regular Expression Tester.
Regex Her Regex Her Regex Her Regex Her Regex Her Regex Her is a real-time online Silverlight Regular Expression Tester.
Nobody is a real-time online Silverlight Regular Expression Tester.
Regex Her o egex Hero Regex Hero Reg ex Hero is a real-time online Silverlight Regular Expression Tester.
Results:
结果是每秒迭代次数为3次运行的中位数--更大的数字=更好的。
01: ^((?!Regex Hero).)*$ 3.914 // Accepted Answer
02: ^(?:(?!Regex Hero).)*$ 5.034 // With Non-Capturing group
03: ^(?>[^R]+|R(?!egex Hero))*$ 6.137 // Lookahead only on the right first letter
04: ^(?>(?:.*?Regex Hero)?)^.*$ 7.426 // Match the word and check if you're still at linestart
05: ^(?(?=.*?Regex Hero)(?#fail)|.*)$ 7.371 // Logic Branch: Find Regex Hero? match nothing, else anything
P1: ^(?(?=.*?Regex Hero)(*FAIL)|(*ACCEPT)) ????? // Logic Branch in Perl - Quick FAIL
P2: .*?Regex Hero(*COMMIT)(*FAIL)|(*ACCEPT) ????? // Direct COMMIT & FAIL in Perl
由于.NET不支持动作动词(*FAIL等),所以我无法测试P1和P2的解决方案。
Summary:
我试着测试了大多数提议的解决方案,对于某些词来说,一些优化是可能的。 例如,如果搜索字符串的前两个字母不一样,答案03可以扩展为^(?>[^R]+|R+(?!egex Hero))*$,从而获得小的性能提升。
但是从总体上看,可读性最强、性能最快的解决方案似乎是使用条件语句的05,或者使用占有式量词的04。我认为Perl的解决方案应该更快、更容易阅读。
^(?!.*hede)计时。/// 此外,对匹配语料库和非匹配语料库的表达式分别进行排序可能更好,因为通常情况下,大多数行都是匹配的,或者大多数行都是不匹配的。
- ikegami 2016-08-23
不是regex,但我发现使用带管道的串行greps来消除噪音是合乎逻辑的,也是很有用的。
例如,搜索一个没有所有评论的apache配置文件------。
grep -v '\#' /opt/lampp/etc/httpd.conf # this gives all the non-comment lines
和
grep -v '\#' /opt/lampp/etc/httpd.conf | grep -i dir
串行grep的逻辑是(不是注释)和(匹配dir)。
grep -v的regex版本。
- Angel.King.47 2011-07-12
good_stuff #comment_stuff这样的线
- Xavi Montero 2013-03-01
有了这个,你就可以避免在每个位置上测试一个提前量。
/^(?:[^h]+|h++(?!ede))*+$/
相当于(对.net而言)。
^(?>(?:[^h]+|h+(?!ede))*)$
旧的答案。
/^(?>[^h]+|h+(?!ede))*$/
/^[^h]*(?:h+(?!ede)[^h]*)*$/
- Alan Moore 2013-04-14
前面提到的(?:(?!hede).)*很好,因为它可以锚定。
^(?:(?!hede).)*$ # A line without hede
foo(?:(?!hede).)*bar # foo followed by bar, without hede between them
但是,在这种情况下,以下内容就足够了。
^(?!.*hede) # A line without hede
这种简化准备加入 "与 "字句。
^(?!.*hede)(?=.*foo)(?=.*bar) # A line with foo and bar, but without hede
^(?!.*hede)(?=.*foo).*bar # Same
由于没有其他人直接回答被问到的问题,我会这样做。
答案是,用POSIX grep,不可能从字面上满足这个要求:
grep "<Regex for 'doesn't contain hede'>" input
原因是POSIX grep只需要与基本正则表达式一起工作,而这些正则表达式根本不足以完成这一任务(由于缺乏交替,它们无法解析所有的正则语言)。
然而,GNU grep实现的扩展允许它。特别是,\|是GNU的BREs实现中的交替运算符。如果你的正则表达式引擎支持交替运算、小括号和Kleene星,并且能够锚定到字符串的开头和结尾,这就是你需要的这种方法。但是请注意,除了这些之外,负数集[^ ... ]非常方便,因为否则,你需要用一个(a|b|c| ... )形式的表达式来代替它们,该表达式列出了不在该集中的每一个字符,这非常繁琐,而且时间过长,如果整个字符集是Unicode的话,那就更麻烦了。
由于形式语言理论的存在,我们可以看到这样的表达方式是怎样的。用GNU grep,答案会是这样的:
grep "^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$" input
(用Grail和一些手工制作的进一步优化发现的)。
您还可以使用实现扩展正则表达式的工具,就像egrep,去掉反斜杠:
egrep "^([^h]|h(h|eh|edh)*([^eh]|e[^dh]|ed[^eh]))*(|h(h|eh|edh)*(|e|ed))$" input
这里有一个测试的脚本(注意它在当前目录下生成了一个文件testinput.txt)。提出的几个表达式未能通过这个测试。
#!/bin/bash
REGEX="^\([^h]\|h\(h\|eh\|edh\)*\([^eh]\|e[^dh]\|ed[^eh]\)\)*\(\|h\(h\|eh\|edh\)*\(\|e\|ed\)\)$"
# First four lines as in OP's testcase.
cat > testinput.txt <<EOF
hoho
hihi
haha
hede
h
he
ah
head
ahead
ahed
aheda
ahede
hhede
hehede
hedhede
hehehehehehedehehe
hedecidedthat
EOF
diff -s -u <(grep -v hede testinput.txt) <(grep "$REGEX" testinput.txt)
在我的系统中,它打印出来了。
Files /dev/fd/63 and /dev/fd/62 are identical
正如预期的那样。
对于那些对细节感兴趣的人来说,所采用的技术是将匹配该词的正则表达式转换为有限自动机,然后通过将每个接受状态改为不接受,反之亦然来反转自动机,然后将得到的FA转换回正则表达式。
正如大家所指出的,如果你的正则表达式引擎支持负向查找,那么正则表达式就简单多了。例如,使用 GNU grep。
grep -P '^((?!hede).)*$' input
但是,这种方法的缺点是需要回溯正则表达式引擎。这使得它不适合使用像 RE2 这样的安全正则表达式引擎的安装,这是一个有理由在某些情况下更喜欢生成的方法。
使用 Kendall Hopkins 优秀的 FormalTheory 库,用 PHP 编写,提供类似于 Grail 的功能,和我自己编写的简化器,我已经能够在给定输入短语(目前仅支持字母数字和空格字符)的情况下编写一个负正则表达式的在线生成器:http://www.formauri.es/personal/pgimeno/misc/non-match-regex/
对于hede来说,它的输出结果是:
^([^h]|h(h|e(h|dh))*([^eh]|e([^dh]|d[^eh])))*(h(h|e(h|dh))*(ed?)?)?$
这等同于上面的内容。
我的做法是这样的。
^[^h]*(h(?!ede)[^h]*)*$
比其他答案更准确、更有效。它实现了 Friedl 的“unrolling-the-loop” 效率技术,并且需要更少的回溯。
在我看来,这是一个更易读的顶级答案的变体。
^(?!.*hede)
基本上,"在行首匹配,当且仅当它没有'hede'时"--因此,该要求几乎直接翻译成了regex。
当然,有可能存在多种失败的要求。
^(?!.*(hede|hodo|hada))
细节:^锚确保了重码引擎不会在字符串的每个位置重试匹配,这将匹配每一个字符串。
开头的^锚是为了代表该行的开始。grep工具一次匹配每一行,在你处理多行字符串的情况下,你可以使用 "m "标志。
/^(?!.*hede)/m # JavaScript syntax
或者说
(?m)^(?!.*hede) # Inline flag
另一个选项是添加一个正向预测并检查hede 是否在输入行中的任何位置,然后我们会否定它,表达式类似于:
^(?!(?=.*\bhede\b)).*$
有字的界限。
该表达式在regex101.com的右上方面板上有解释,如果你想探索/简化/修改它,在这个链接中,如果你愿意,你可以观看它如何与一些样本输入进行匹配。
RegEx Circuit
jex.im 可视化正则表达式。

^(?!.*\bhede\b).*$。
- Wiktor Stribiżew 2021-10-22
如果你想匹配一个字符来否定一个词,类似于否定字符类的。
比如说,一个字符串。
<?
$str="aaa bbb4 aaa bbb7";
?>
请勿使用。
<?
preg_match('/aaa[^bbb]+?bbb7/s', $str, $matches);
?>
使用。
<?
preg_match('/aaa(?:(?!bbb).)+?bbb7/s', $str, $matches);
?>
注意"(?!bbb)."既不是lookbehind也不是lookahead,它是lookcurrent,例如:
"(?=abc)abcde", "(?!abc)abcde"
(?!)。正的lookahead'的前缀是(?=,而相应的lookbehind前缀分别是(?<!和(?<=。lookahead意味着你读取下一个字符(因此是 "超前")而不消耗它们。后看意味着你检查已经被消耗的字符。
- Didier L 2012-05-21
(?!abc)abcde怎么会有任何意义。
- Scratte 2021-02-05
OP没有指定或Tag帖子来说明Regex将在什么情况下(编程语言、编辑器、工具)使用。
对我来说,我有时需要在使用Textpad编辑文件时这样做。
Textpad支持一些Regex,但不支持lookahead或lookbehind,所以需要一些步骤。
如果我希望保留所有 Do NOT 包含字符串 hede 的行,我会这样做:
1.搜索/替换整个文件,在包含任何文本的每一行的开头添加一个独特的 "标签"。
Search string:^(.)
Replace string:<@#-unique-#@>\1
Replace-all
2、删除所有包含
hede字符串的行(替换字符串为空)。
Search string:<@#-unique-#@>.*hede.*\n
Replace string:<nothing>
Replace-all
3.此时,所有剩余的行@不要@包含字符串
hede。删除所有行中唯一的 "标签"(替换字符串为空)。
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
现在您已经删除了包含字符串 hede 的所有行的原始文本。
如果我希望 Do Something Else 仅显示 Do NOT 包含字符串 hede,我会这样做:
1.搜索/替换整个文件,在包含任何文本的每一行的开头添加一个独特的 "标签"。
Search string:^(.)
Replace string:<@#-unique-#@>\1
Replace-all
2.对于所有包含字符串
hede的行,删除唯一的 "标签"。
Search string:<@#-unique-#@>(.*hede)
Replace string:\1
Replace-all
3。此时,所有以唯一“标签”Do NOT 开头的行都包含字符串
hede。我现在可以只对这些行执行我的 Something Else。
4.当我完成后,我从所有行中删除唯一的 "Tag"(替换字符串是空的)。
Search string:<@#-unique-#@>
Replace string:<nothing>
Replace-all
自从ruby-2.4.1推出以来,我们可以在Ruby的正则表达式中使用新的Absent操作符。
来自官方的文件的信息
(?~abc) matches: "", "ab", "aab", "cccc", etc.
It doesn't match: "abc", "aabc", "ccccabc", etc.
因此,在您的情况下,^(?~hede)$ 为您完成了这项工作
2.4.1 :016 > ["hoho", "hihi", "haha", "hede"].select{|s| /^(?~hede)$/.match(s)}
=> ["hoho", "hihi", "haha"]
通过 PCRE 动词 (*SKIP)(*F)
^hede$(*SKIP)(*F)|^.*$
这将完全跳过包含精确字符串hede的那一行,而匹配所有其余的行。
执行的部分:
让我们考虑一下上述词条,把它分成两部分。
部分在
|符号之前。部分不应该被匹配。^hede$(*SKIP)(*F)部分在
|符号之后。部分应匹配。^.*$
第1部分
Regex引擎将从第一部分开始执行。
^hede$(*SKIP)(*F)
解释:
^断言我们处于开始阶段。hede匹配字符串hede。$断言我们在行尾。
所以包含字符串hede的那一行将被匹配。一旦重组引擎看到下面的(*SKIP)(*F)(注意:你可以把(*F)写成(*FAIL))动词,就会跳过,使匹配失败。在PCRE动词旁边添加的|称为改变或逻辑OR运算符,它反过来匹配所有行的每个字符之间存在的边界,除了包含精确字符串hede的行。请看演示这里。也就是说,它试图匹配剩余字符串中的字符。现在,第二部分中的regex将被执行。
部分2@
^.*$
解释:
TXR语言支持REGX的否定功能。
$ txr -c '@(repeat)
@{nothede /~hede/}
@(do (put-line nothede))
@(end)' Input
一个更复杂的例子:匹配所有以a开头,以z结尾,但不包含子串hede的行:
$ txr -c '@(repeat)
@{nothede /a.*z&~.*hede.*/}
@(do (put-line nothede))
@(end)' -
az <- echoed
az
abcz <- echoed
abcz
abhederz <- not echoed; contains hede
ahedez <- not echoed; contains hede
ace <- not echoed; does not end in z
ahedz <- echoed
ahedz
Regex否定法本身并不特别有用,但当你也有相交时,事情就变得有趣了,因为你有一整套的布尔集合操作:你可以表达 "与此相匹配的集合,但与此相匹配的事物除外"。
您的代码中的两个正则表达式可能更易于维护,一个进行第一个匹配,然后如果匹配,则运行第二个正则表达式以检查您希望阻止的异常情况,例如 ^.*(hede).* 然后在中具有适当的逻辑你的代码。
好吧,我承认这并不是对所发布问题的真正答案,而且它也可能比单一的重合词使用更多的处理。但是对于那些来这里寻找快速紧急修复异常情况的开发者来说,这个解决方案不应该被忽视。
下面的函数将帮助你获得你所需要的输出
<?PHP
function removePrepositions($text){
$propositions=array('/\bfor\b/i','/\bthe\b/i');
if( count($propositions) > 0 ) {
foreach($propositions as $exceptionPhrase) {
$text = preg_replace($exceptionPhrase, '', trim($text));
}
$retval = trim($text);
}
return $retval;
}
?>
我想添加另一个示例,如果您尝试匹配包含字符串 X 但不包含字符串 Y 的整行。
例如,假设我们要检查我们的 URL/字符串是否包含“tasty-treats”,只要它在任何地方都不包含“chocolate” .
这个regex模式会起作用(在JavaScript中也起作用)。
^(?=.*?tasty-treats)((?!chocolate).)*$
(全局的,多行的标志在例子中)
交互式示例:https://regexr.com/53gv4
Matches
(这些网址包含“tasty-treats”,也不包含“chocolate”)
- example.com/tasty-treats/strawberry-ice-cream
- example.com/desserts/tasty-treats/banana-pudding
- example.com/tasty-treats-overview
Does Not Match
(这些URL在某处含有"巧克力"--所以即使它们含有"美味的点心",也不会匹配。)
- example.com/tasty-treats/chocolate-cake
- example.com/home-cooking/oven-roasted-chicken
- example.com/tasty-treats/banana-chocolate-fudge
- example.com/desserts/chocolate/tasty-treats(巧克力)。
- example.com/chocolate/tasty-treats/desserts
只要您处理的是行,只需标记否定匹配项并定位其余匹配项。
事实上,我使用这个技巧与sed,因为^((?!hede).)*$看起来不支持它。
For the desired output
标记消极的匹配:(例如带有
hede的行),使用一个根本不包括在整个文本中的字符。为此,一个表情符号可能是一个不错的选择。s/(.*hede)/🔒\1/g针对其余的(未标记的字符串:例如,没有
hede的行)。假设你想只保留目标,并删除其余的(如你想):s/^🔒.*//g
For a better understanding
假设你想删除目标。
标记消极的匹配:(例如带有
hede的行),使用一个根本不包括在整个文本中的字符。为此,一个表情符号可能是一个不错的选择。s/(.*hede)/🔒\1/g针对其余的(未标记的字符串:例如,没有
hede的行)。假设你想删除目标:s/^[^🔒].*//g删除标记。
s/🔒//g
^((?!hede).)*$ 是一个优雅的解决方案,除了因为它消耗字符,您将无法将它与其他条件结合起来。例如,假设您想检查“hede”的不存在和“haha”的存在。这个解决方案会起作用,因为它不会消耗字符:
^(?!.*\bhede\b)(?=.*\bhaha\b)
How to use PCRE's backtracking control verbs to match a line not containing a word
这里有一个我以前没有见过的方法。
/.*hede(*COMMIT)^|/
How it works
首先,它试图在该行的某处找到“hede”。如果成功,此时,(*COMMIT) 告诉引擎不仅在失败的情况下不要回溯,而且在这种情况下也不要尝试任何进一步的匹配。然后,我们尝试匹配一些不可能匹配的东西(在本例中为^)。
如果一行不包含 "hede",那么第二种选择,即一个空的子模式,就能成功地匹配主题字符串。
这种方法并不比负数前瞻更有效,但我想我还是把它扔在这里,以防有人发现它很有趣,并在其他更有趣的应用中找到它的用途。
一个更简单的解决方案是使用not操作符!。
你的if语句将需要匹配 "包含 "而不是匹配 "排除"。
var contains = /abc/;
var excludes =/hede/;
if(string.match(contains) && !(string.match(excludes))){ //proceed...
我相信RegEx的设计者已经预见到了not操作符的使用。
也许你会在谷歌上找到这个,因为你想写一个能够匹配不包含子串的行段(而不是整行)的重词。我花了点时间才弄明白,所以我将分享:
给定一个字符串。
<span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>
我想匹配不包含子串 "bad "的<span>标签。
/<span(?:(?!bad).)*?>将与<span class=\"good\">和<span class=\"ugly\">相匹配。
注意,有两组(层)括号。
- 最里面的一个是用于负数前瞻(它不是一个捕获组)。
- 最外层被Ruby解释为捕获组,但我们不希望它是一个捕获组,所以我在它的开头添加了?: ,它就不再被解释为捕获组了。
在Ruby中进行演示。
s = '<span class="good">bar</span><span class="bad">foo</span><span class="ugly">baz</span>'
s.scan(/<span(?:(?!bad).)*?>/)
# => ["<span class=\"good\">", "<span class=\"ugly\">"]
使用ConyEdit,你可以使用命令行cc.gl !/hede/来获取不包含重码匹配的行,或者使用命令行cc.dl /hede/来删除包含重码匹配的行。它们的结果是一样的。
# 一个简单的方式
import re
skip_word = 'hede'
stranger_char = '虩'
content = '''hoho
hihi
haha
hede'''
print(
'\n'.join(re.findall(
'([^{}]*?)\n'.format(stranger_char),
content.replace(skip_word, stranger_char)
)).replace(stranger_char, skip_word)
)
# hoho
# hihi
# haha