Java HashMap的负载因子
1.概述
在这篇文章中,我们将看到Java的HashMap中的负载因子的意义,以及它是如何影响Map的性能的。
2.什么是HashMap
HashMap类属于Java集合框架,提供了Map接口的基本实现。当我们想以键值对的方式存储数据时,我们可以使用它。这些键值对被称为Map条目,由Map.Entry类表示。
3.HashMap的内部结构
在讨论负载率之前,让我们先回顾一下几个术语。
-
- 散列法
- 容量
- 阈值
- 重新散列
- 碰撞
HashMap的工作原理是散列--一种将对象数据映射到某些代表性整数值的算法。散列函数被应用于键对象,以计算桶的索引,以便存储和检索任何键值对。
Capacity是HashMap的桶的数量。初始容量是创建Map 时的容量。HashMap的默认初始容量是16。
随着HashMap中元素数量的增加,容量也会扩大。负载因子是决定何时增加Map容量的度量。默认的负载因子是容量的75%。
HashMap的阈值大约是当前容量和负载因子的乘积。重新散列是重新计算已存储条目的散列码的过程。简单地说,当哈希表中的条目数量超过阈值时,将对Map进行重新哈希处理,使其具有大约两倍于之前的桶的数量。
当一个哈希函数为两个不同的键返回相同的桶的位置时,就会发生碰撞。
让我们来创建我们的HashMap。
Map<String, String> mapWithDefaultParams = new HashMap<>();
mapWithDefaultParams.put("1", "one");
mapWithDefaultParams.put("2", "two");
mapWithDefaultParams.put("3", "three");
mapWithDefaultParams.put("4", "four");
这里是我们的Map的结构:
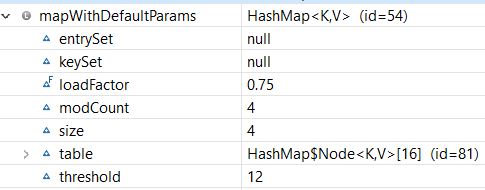
我们看到,我们的HashMap是以默认的初始容量(16)和默认的负载因子(0.75)创建的。另外,阈值是16*0.75=12,这意味着在添加第12个条目(键值对)之后,它的容量将从16增加到32。
4.自定义初始容量和负载因子
在上一节中,我们用一个默认的构造函数创建了我们的HashMap。在接下来的章节中,我们将看到如何创建一个HashMap ,将初始容量和负载因子传递给构造函数。
4.1.具有初始能力
首先,让我们创建一个具有初始容量的Map。
Map<String, String> mapWithInitialCapacity = new HashMap<>(5);
它将创建一个空的Map,具有初始容量(5)和默认的负载因子(0.75)。
4.2.带初始容量和负载因子
同样地,我们可以使用初始容量和负载因子来创建我们的Map。
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5, 0.5f);
在这里,它将创建一个空的Map,初始容量为5,负载因子为0.5。
5.性能
虽然我们可以灵活地选择初始容量和负载因子,但我们需要明智地选择它们。它们都会影响Map的性能。让我们深入了解这些参数与性能的关系。
5.1.复杂性
我们知道,HashMap内部使用哈希代码作为存储键值对的基础。如果hashCode()方法写得很好,HashMap会把项目分布在所有的桶中。因此,HashMap在恒定时间内O(1)存储和检索条目。
然而,当项目的数量增加而桶的大小固定时,问题就出现了。它在每个桶中会有更多的项目,并会干扰时间的复杂性。
解决办法是,当项目数量增加时,我们可以增加桶的数量。然后我们可以在所有的桶中重新分配项目。这样一来,我们就能保持每个桶中的物品数量不变,并保持O(1)的时间复杂性。
在这里,负载因子帮助我们决定何时增加桶的数量。随着负载因子的降低,将有更多的空闲桶,因此,碰撞的机会也会减少。这将帮助我们的Map取得更好的性能。因此,我们需要保持低的负载因子,以实现低的时间复杂性。
一个HashMap的空间复杂度通常为O(n),其中n是条目的数量。较高的负载因子值会降低空间开销,但会增加查找成本。
5.2 重新散列
当Map中的条目数量超过阈值限制时,Map的容量就会翻倍。如前所述,当容量增加时,我们需要将所有条目(包括现有条目和新条目)平均分配到所有桶中。这里,我们需要重新散列。也就是说,对于每个现有的键值对,以增加的容量为参数再次计算哈希代码。
基本上,当负载因子增加时,复杂性也会增加。重新散列是为了保持所有操作的低负载因子和低复杂性。
让我们来初始化我们的Map。
Map<String, String> mapWithInitialCapacityAndLF = new HashMap<>(5,0.75f);
mapWithInitialCapacityAndLF.put("1", "one");
mapWithInitialCapacityAndLF.put("2", "two");
mapWithInitialCapacityAndLF.put("3", "three");
mapWithInitialCapacityAndLF.put("4", "four");
mapWithInitialCapacityAndLF.put("5", "five");让我们看一下Map的结构。
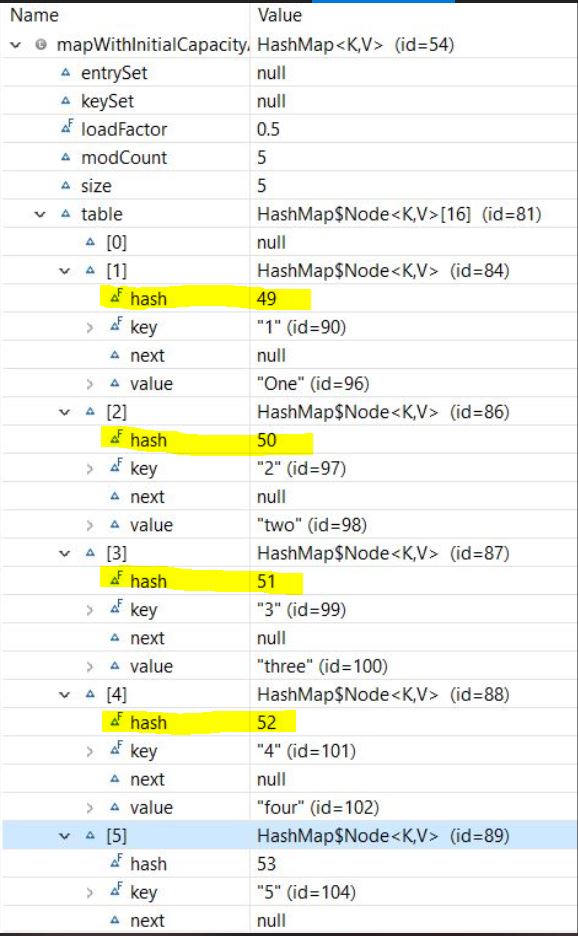
现在,让我们在我们的Map上添加更多的条目:
mapWithInitialCapacityAndLF.put("6", "Six");
mapWithInitialCapacityAndLF.put("7", "Seven");
//.. more entries
mapWithInitialCapacityAndLF.put("15", "fifteen");让我们再观察一下我们的Map结构:
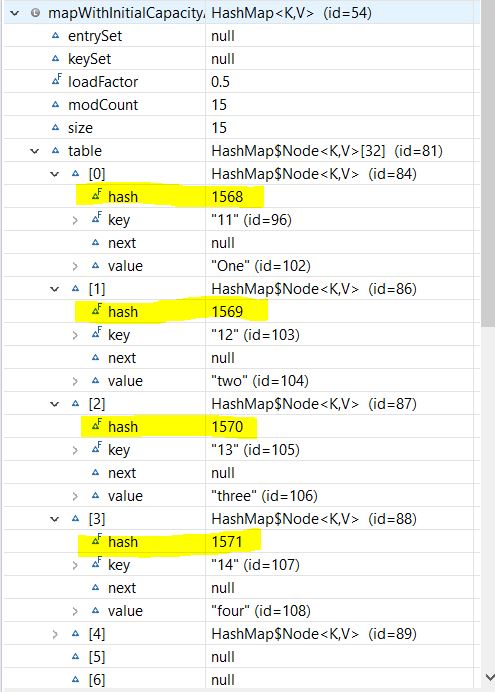
虽然重新散列有助于保持低复杂度,但这是一个昂贵的过程。如果我们需要存储大量的数据,我们应该创建有足够容量的HashMap。这比自动重新散列更有效。
5.3.碰撞
由于哈希码算法不好,可能会发生碰撞,而且常常会拖累Map的性能。
在Java 8之前,Java中的HashMap通过使用LinkedList来存储Map条目来处理碰撞。如果一个键最终出现在已经存在另一个条目的同一个桶中,它就会被添加到LinkedList的头部。在最坏的情况下,这将使复杂性增加到O(n)。
为了避免这个问题,Java 8及以后的版本使用平衡树(也称为红黑树)而不是LinkedList来存储碰撞的条目。这提高了HashMap的最坏情况下的性能,从O(n)到O(log n)。
HashMap最初使用LinkedList。当条目数超过某个阈值时,它将用平衡的二叉树替换LinkedList。TREEIFY_THRESHOLD常数决定这个阈值。目前,这个值是8,这意味着如果同一个桶里有超过8个元素,Map将使用一棵树来容纳它们。
6.结语
在这篇文章中,我们讨论了最流行的数据结构之一。HashMap。我们还看到了负载因子与容量一起是如何影响其性能的。
像往常一样,本文的代码示例可在GitHub上获得。