ASCII 码简介
一、简介
ASCII(美国信息交换标准代码)代码由 7 位二进制标准组成,用于对一组 128 个图形和控制符号进行编码。
具体来说,ASCII 表包含 95 个图形符号。这些符号包括拉丁字母(小写和大写)、常见标点符号、常见数学符号和阿拉伯数字。
ASCII 表还包含 33 个控制符号。这些符号用于管理处理并提供 ASCII 编码信息的元数据。
在本文中,首先,我们将了解 ASCII 的历史和文档。接下来,我们深入到ASCII表中来了解一下每个符号是如何编码的。
在了解了理论背景之后,我们将了解如何将特定的符号和单词从图形形式编码为十进制 ASCII 代码,最后编码为二进制代码。同样,我们将了解如何解码二进制/十进制 ASCII 代码。
最后,我们将简要回顾一些 ASCII 变体及其应用场合。
2. 一点点历史
最初,电报传输中使用的代码激发了 ASCII 代码的发展。因此,它被设计为与基于 7 位的电传打印机配合使用。然而,ASCII 代码的开发人员还计划了适用于电传打字机以外的设备的代码。
美国标准协会(即今天的美国国家标准协会)于 1963 年提出了 ASCII。此后,该组织多次审查了 ASCII,并一直对其进行维护。
ASCII 中包含的额外非电报代码以及组织良好且排序的代码分布(与早期的电报代码相比)使 ASCII 于 1968 年成为美国标准联邦计算机通信语言。
随着互联网的兴起,ASCII 在接下来的几年里迅速传播。 通过对电子邮件和 HTML 页面的字符进行编码,ASCII 代码变得特别流行。
自 2008 年以来,UTF-8 超过 ASCII 成为最常见的互联网编码。然而,UTF-8 嵌入了 ASCII 作为其前 128 个代码,并且仅用 128 个额外代码扩展了该表。
3.ASCII码
如上所述,ASCII 由 7 位代码和 128 个符号(95 个图形符号和 33 个控制符号)组成。
最重要的是,ASCII 规定特定的位序列(代码)代表特定的符号。因此,例如,ASCII 使数字设备能够处理、存储和呈现人类自然识别的数据。
ASCII 代码通常显示在一个表中,称为 ASCII 表,其中包含与每个代码关联的符号,以及它们的描述和十进制/二进制代码表示形式:
ASCII 表将大多数控制符号的代码范围从 0 到 31 进行分组。唯一的例外是符号 DEL,其代码为 127。此例外解决了电传打字机纠正打字错误的过程。
请注意,当操作员按键时,电传打字机会打孔卡。因此,没有可用的退格功能。这样,纠正错误的过程包括将打孔卡退回到错误位置,并用读取和处理打孔卡时忽略的代码替换其各自的代码。
电传打字机通常通过在错误位置打孔来表示忽略代码,生成 ASCII DEL 代码 (127)。
图形符号的代码在ASCII表中为32到126之间。 ASCII 图形符号包括拉丁字母、阿拉伯数字、标点符号和数学运算符等。
特别是,我们不将空格 (32) 识别为可打印符号。因此,空格(32)被专门归类为不可见的图形符号。
最后,ASCII 图形符号的顺序遵循一种被称为 ASCIIbetical 的特定组织。 ASCIIbetical 顺序将大写字母分配在小写字母之前(例如,“Z”在“a”之前)。此外,数字位于字母之前,其他符号则接受字母和数字的夹层编码。
4. ASCII 编码和解码过程
将随机字符串编码为二进制 ASCII 代码通常需要一个 ASCII 表,其中包含每个字符串字符各自的十进制值。编码后,数字设备可以处理、存储或传输这些代码。然而,向此类设备的操作人员显示 ASCII 涉及将代码从二进制解码为可读版本。
在下面的小节中,我们将学习 ASCII 的编码和解码过程。
4.1.从可读字符串到二进制 ASCII
为了演示如何将字符序列转换为二进制 ASCII 代码,我们将使用字符串“Baeldung”并对其逐步执行编码过程。
首先,我们查找 ASCII 表以确定字符串中每个字符对应的十进制值: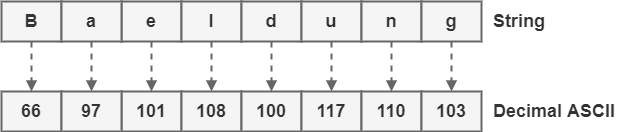
当我们使用拉丁字母时,请务必注意 ASCII 区分大小写。因此,在我们的示例中,“B”的代码(66)与“b”的代码(98)不同。
在定义了十进制ASCII码之后,我们就可以将它们转换为二进制代码。为了做到这一点,我们把每个十进制代码转录为7位代码。二进制ASCII码的每个位置P(换句话说,每个比特)表示2^P的值。此外,位的重要性从右向左增长。这样一来,二进制ASCII码就有以下结构:
有了这种结构,为了得到十进制ASCII码的相应二进制代码,我们应该给位置P分配一个比特1,使其数值之和达到十进制ASCII码的结果。其他位置则得到一个比特0。考虑到 "Baeldung"的编码过程,我们有以下的二进制ASCII码: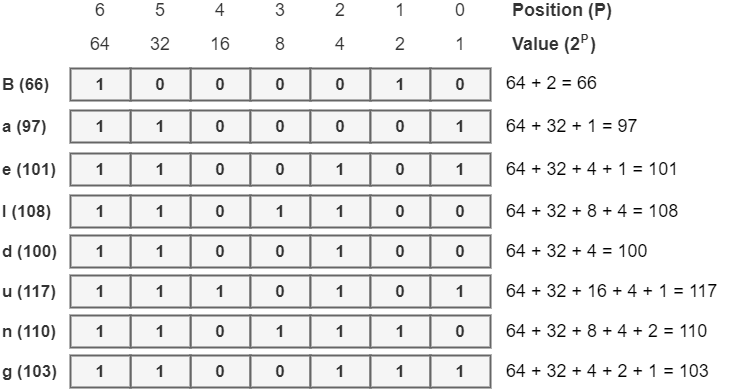
因此,字符串“Baeldung”的二进制 ASCII 代码为 1000010 1100001 1100101 1101100 1100100 1110101 1101110 1100111。
4.2.从二进制 ASCII 到可读字符串
为了演示从二进制 ASCII 到可读字符串的解码过程,我们将使用以下代码:1010011 1100011 1101001 1100101 1101110 1100011 1100101。
为了执行二进制ASCII码的解码过程,我们将使用之前用于编码过程的相同的位置/值结构。然而,现在,我们必须用所提供的二进制代码的各自比特来填充这些位置。然后,我们将位置的值与位数1相加,得到十进制代码: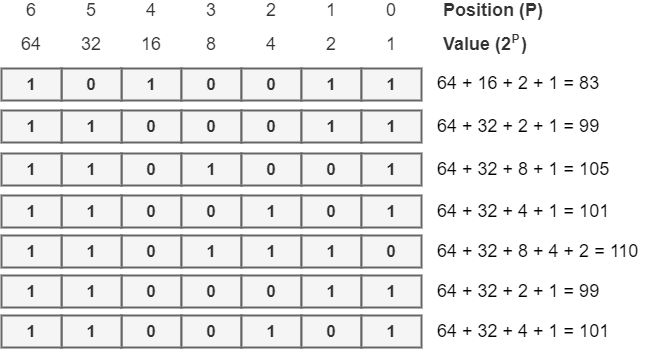
接下来,我们查找 ASCII 表,将十进制代码转换为可读的字符串:
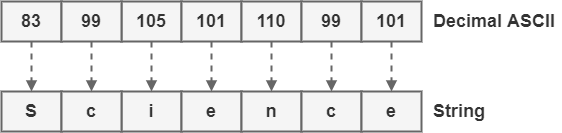
最后,我们得出结论,所提供的 ASCII 代码的可读字符串是“Science”。
5. ASCII 变体
随着计算机技术的普及,特定的标准化机构采用了 ASCII 码来处理特定语言中使用的新符号。这些符号的示例是带有重音符号和变音符的字母。
鼓励创建 ASCII 变体的另一个现象是 8 位(以及后来的 16、32 和 64 位)计算机体系结构的兴起。编程语言识别的最小数据类型通常为 8 位字节。因此,新的编码经常使用额外的位来扩大 ASCII 表。
新的编码保留了 ASCII 的原始表(0 到 127)并用新符号对其进行了扩展。特别令人感兴趣的两个 8 位编码是:
- Windows 1252:单字节编码,使用 123 个额外符号扩展 ASCII 表. Windows 1252 提供了 ASCII 表中未考虑的几个西方拉丁字符的代码。目前,Windows 1252 表中只有 5 个代码未使用。
- UTF-8:单字节编码,用 128 个额外符号扩展 ASCII 表。与 Windows 1252 中一样,UTF-8 的新符号包含多个西方拉丁字符。但是,其中一些额外的符号和代码与 Windows 1252 表中的不同。我们强调 UTF-8 是 Unicode 标准的一部分。 Unicode 标准为大多数现有书写系统中的符号提供了二进制代码。但是,为此,Unicode 可能需要两个 (UTF-16) 或四个 (UTF-32) 字节来对特定符号进行编码。
六,结论
在本文中,我们研究了 ASCII 码和表格。首先,我们回顾了ASCII 的历史。接下来,我们分析了ASCII 表和代码并了解了该标准的组织方式。然后,我们学习了如何使用 ASCII 编码/解码通用字符串。最后,我们了解了最常见的 ASCII 变体。
我们可以得出结论,ASCII 是一个重要的标准,它启发并构成了当前最流行的信息编码标准,例如 UTF-8。